Deliberate Practice$\ ^{[1]}$:to identify your weakest areas and direct a massive effort on improving those areas without worrying about areas in which you are already good.
这是我在阅读西瓜书第二章时的一个遗留问题,是关于偏差-方差窘境(Bias-Variance Dilemma)的内容。
首先要解释Bias-Variance Tradeoff,也就是偏差-方差权衡,譬如当前有一个拟合任务,需要构造一个多项式函数去拟合它,函数可以构造成这样:
$$
y=a_0+a_1x+a_2x^2+…+a_nx^n
$$
如何确定$n$的大小就是一个偏差-方差的权衡问题,。图像上直观地看则是为了确定这条曲线的“弯曲程度”。
曲线拟合和机器学习:前者是利用数据尽可能地拟合出一条完美的曲线;后者则是在有限的数据规模内进行学习,目的是遇到未知数据时能够做出最好的判断。
模型的泛化能力可以由泛化误差来描述,泛化误差越小,模型的期望泛化能力越强。模型$f$在数据集$D$上的泛化误差可以分解为偏差$bias$、方差$var$、噪声$\epsilon$之和:
$$
E(f;D)=\mbox{bias}^2(x)+\mbox{var}(x)+\epsilon^2
$$
递推可以在西瓜书P45翻到。
噪声指的是学习算法本身固有的误差(系统误差)和数据集的噪声。当保证数据集十分纯净的时候,人为可控的部分就只有偏差和方差了。于是机器学习中存在偏差-方差窘境:偏差(bias)描述的是模型的拟合能力,偏差过大可以认为是欠拟合;方差(variance)则描述的是数据集的情况,方差过大可以认为是在数据集上过拟合。二者无法同时达到最小,只能取一个平衡点。
总结一下特点:
- 高偏差的模型:训练集的错误率高,验证集和训练集的错误率类似。
- 高方差的模型:训练集错误率低,验证集高。
下图描述了一些简单的处理方法: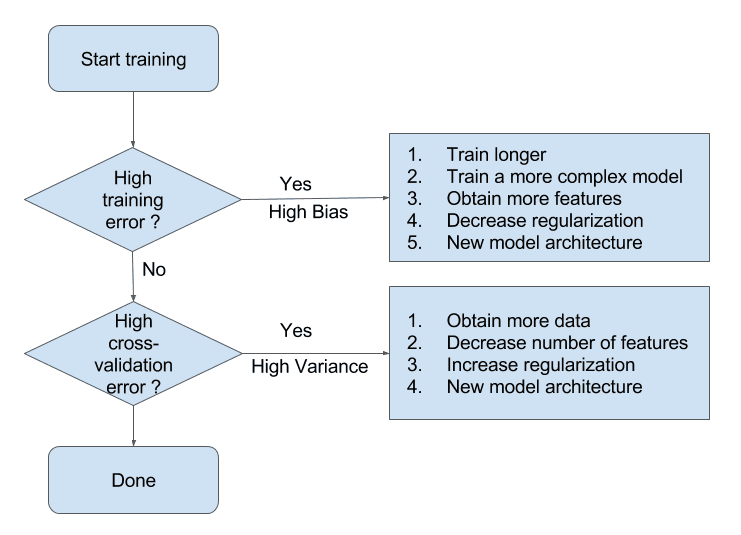
Reference
[1]. https://www.learnopencv.com/bias-variance-tradeoff-in-machine-learning/